
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- AWS Crawler
- Spark
- EMR 구조
- lazy evaluation
- 프로그래머스 큰 수 만들기
- 데이터 수집
- Spark 최적화
- 프로그래머스
- 데이터엔지니어링
- ORACLE문법
- 데이터베이스복사
- Catalyst Optimizer
- 실행엔진
- 문맥교환
- 카프카
- 하둡에코시스템
- 하둡1.0
- 서버간 복사
- 스파크
- freenom
- Databricks
- kafka 설치
- 빌드도구
- 런타임데이터영역
- 하둡2.0
- 데이터파이프라인
- 프로그래머스힙
- 지연연산
- 하둡
- ORACLE MSSQL차이
- Today
- Total
띵유로그
[SPARK] SPARK DATAFRAME이란 - RDD와 어떻게 다른가? 본문
Spark 의 프로그래밍 API에는 고수준 API(구조적 API)와 저수준 API가 있습니다.
고수준 API(구조적 API)
- DataFrame
- SQL
- Dataset
저수준 API
- RDD
이번 포스팅에서는 고수준 API인 DataFrame에 대해 알아보고, RDD와 어떤점이 다른지 적어보려한다.
짧게 말하면 DataFrame은 API가 간결하면서 쿼리 최적화를 자동으로 해주기때문에 RDD보다 성능이 더 좋다.
보통 물리적으로 데이터 배치를 세밀하게 제어해야하는 상황에서 RDD를 사용한다.
DataFrame은 RDD의 특징을 상속받고있기때문에 RDD에 대한 이해가 선행되어야한다.
RDD란?
RDD (Resilient Distributed Database)
RDD란 오류에 강한 분산 데이터베이스이다. 만약, falut 가 발생해도 다시 재계산하면된다.
falut에 강한(tolerance한) 이유는 RDD가 Directed Acyclic Graph 구조를 따르기 떄문이다.
RDD 특징 1) DAG 구조
이전 Data의 상태는 변경시킬 수 없으며 앞으로의 상태만 변경시킬 수 있다. 이러한 구조를 가진 덕에 falut 에 강하다(tolerant하다)

RDD 특징 2) Distributed Dataset
데이터가 클러스터의 여러개의 node의 분산되어 저장된다.
따라서 작업을 할 때에는 각 클러스터가 본인이 가진 data에만 접근하여 작업하며, 결과는 합산후 관리자(driver)에게 report한다.
DataFrame API 란?
SPARK의 DataFrame API은 RDD의 resilient, distributed하다는 특징을 상속받고 METADATA를 가진다.
SPARK의 DataFrame API는 METADATA를 통해 RDD API 위에서 최적화작업을 할 수 있다.
따라서 DataFrame을 통해 SQL문을 날려 효율적으로 정보를 읽고 분석할 수 있다.
<METADATA에서 가지고 있는 정보>
- 데이터저장정보
- DAG를 통해 적용하고자하는 transformation
- 데이터셋의 칼럼수
- 데이터 타입
DataFrame 특징
1. 행 개체의 분산 컬렉션 : 열로 구성된 분산 데이터 컬렉션이다. 개념적으로는 관계형 데이터베이스의 테이블이랑 동일최적화 기능이 뛰어나다
2. 데이터 처리 : 정형, 비정형 데이터 형식과 스토리지 시스템(HDFS, HIVE) 처리 가능.
3. Catalyst Optimizer를 사용한 최적화 : transformation시 만들어지는 Tree기반의 Optimizer이다. 참고
DataFrame는 어떤 언어를 사용하던지 RDD보다 연산시간이 짧다.
RDD는 개발자가 최적화를 해야하지만, Dataframe은 최적화된 플랜을 만들어내는것을 Catalyst가 대신해주기 때문이다.
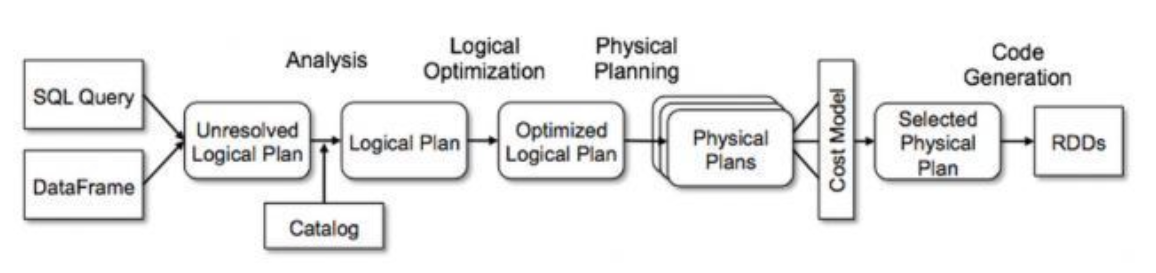
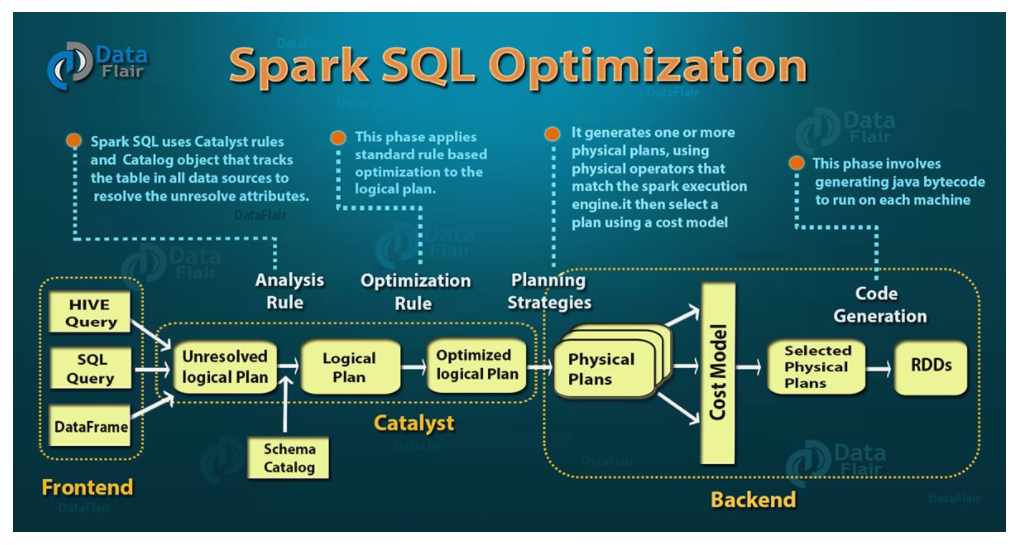
쿼리를 Python, R, Scala 중 어떤 언어로 작성하던지, Spark DataFrame은 Unresolved Logical Plan이라고 불리는 Step을 거친다. 그 후에 Data Catalog를 보고 데이터 source가 무엇인지, 데이터 type이 무엇인지를 알아낸다. 그 이후에 Logical Plan을 만들어낸다. ( Catalyst가 만약 당신이 하고있는게 이상하다고 판단하면, 작성한 query plan을 재구성할 수도 있다. )
최적화하여 Logical Plan을 만든 후 Physical Plan도 만든다. 그중 선택하여 Code Generation해서 요약한것이 RDD이다.
4. Hive 호환성
5. 텅스텐 : 메모리, CPU 성능을 개선하는 프로젝트로, Dataframe, Dataset에 적용.
6. 프로그래밍 언어 지원 : JAVA, SCALA, PYTHON, R
DataFame, RDD가 쿼리를 최적화 하는 방법
1. Analyzing a logical plan to resolve references
2. Logical plan optimization <- Catalyst Optimizer를 거침
<Rule Based Optimization>
1) Constant Folding
- 상수, 리터럴로 된 표현식을 runtime이 아닌 compile time에 계산
2) Predicate Pushdown
- subQuery 밖에 있는 where절을 subQuery로 밀어넣음
- join 후 filter가 아닌 filter 후 join
3) Projection Pruning
- 연산에 필요한 컬럼만가져옴
3. 여러개의 Physical Plan 중 cost Model을 통해 하나로 선택
4. Code generation
: Physical Plan을 JAVA Byte code로 변환
'DataEngineering > SPARK' 카테고리의 다른 글
| [스파크] RDD - Double RDD 전용 함수 (0) | 2021.03.08 |
|---|---|
| [스파크]RDD연산자2(sample, take, takeSample) (0) | 2021.03.08 |
| [스파크] RDD연산자 (0) | 2021.03.08 |
| [스파크] RDD 개요 (0) | 2021.03.08 |
| [SPARK] SPARK - ORIENTATION (0) | 2020.11.25 |

