
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Catalyst Optimizer
- 하둡2.0
- 데이터엔지니어링
- 빌드도구
- 문맥교환
- freenom
- 런타임데이터영역
- 프로그래머스힙
- 데이터베이스복사
- 데이터파이프라인
- 실행엔진
- Databricks
- lazy evaluation
- ORACLE MSSQL차이
- 하둡1.0
- Spark
- ORACLE문법
- 하둡에코시스템
- 프로그래머스
- kafka 설치
- EMR 구조
- 카프카
- 데이터 수집
- 프로그래머스 큰 수 만들기
- 스파크
- Spark 최적화
- AWS Crawler
- 서버간 복사
- 하둡
- 지연연산
- Today
- Total
띵유로그
빅데이터 - 플럼, 카프카 (수집) 본문
이러다가는 열심히 공부한 하둡을 다 잊어버릴 것 같아 블로그에 적기로 했다.
위키북스의 실무로 배우는 빅데이터 기술 이라는 책으로 공부했다.
책에서 제공하는 코드를 통해 스마트카 상태정보, 운전자 운행 로그를 수집후에 적재하고 분석하는 과정까지 진행해보았다.
공부한 내용을 수집, 적재, 처리 및 탐색, 분석 및 응용으로 나누어 글을 작성하겠다.
이번 글은 수집이다.
수집과정에서의 각 SW의 사용 용도를 요약하면 아래와 같이 나타낼 수 있다.
- 로그 수집 : 플럼
- 로그 이벤트 처리 : 스톰
- 버퍼링 및 트랜잭션 처리 : 카프카
플럼을 통해 로그를 수집하고 스톰으로 로그 이벤트를 처리하는데, 그 사이에서의 안정적인 수집을 위해 버퍼링과 트랜잭션 처리를 하는것이 카프카이다.
1. 플럼
- Source : 데이터를 수집후 channel로 전달.
- Channel : Source 와 Sink를 연결. 통로 역할을 하며 데이터를 버퍼링하는 컴포넌트이다.
메모리, 파일, 데이터베이스를 채널의 저장소로 활용한다.
- Sink : 수집한 데이터를 Channel로 부터 전달받아 최종 목적지에 저장한다. (적재)
- Interceptor : Source와 Channel 사이에서 데이터를 필터링하고, 가공한다. (필요시 사용)
예를들어 수집한 데이터에서 null 값 처리를 한다거나, 데이터 특성에 따라 서로 다른 sink로 보내고싶을 때 사용한다.
- Agent : Source -> (Interceptor) -> Channel -> Sink 순으로 구성된 작업단위. 독립된 인스턴스로 생성한다.
한개의 agent에서 두개 이상의 Source -> (Interceptor) -> Channel -> Sink 컴포넌트 구성도 가능.

플럼 한 줄 요약.
|
한마디로 말하면 Source에서 데이터를 수집하고, Channel에 임시저장해두었다가 Sink로 보낸다.
|
원천 시스템은 하나이지만, 높은 성능과 안정성이 필요할 때는 아래와 같은 아키텍쳐를 사용하기도 한다.

아래 그림은 원천 시스템이 많고, 대규모 데이터가 유입될 때 사용되는 아키텍쳐다. 에이전트 1,2,3으로 수집하고,
에이전트 5에서 aggregation하며 에이전트 4에서 이중화를 통해 안전성을 보장한다.
(이런 구조가 잘 쓰이지는 않는다고 함..)
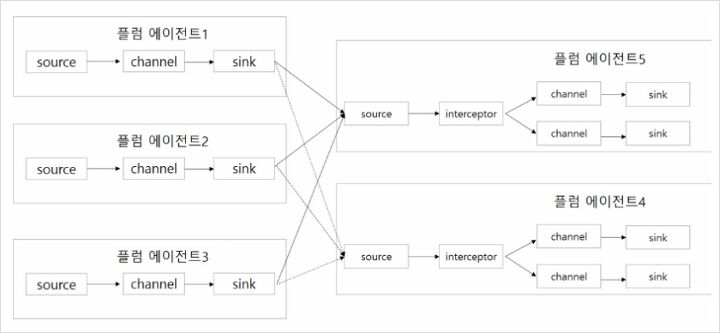
로그의 발생 유형에 따라 다르게 에이전트를 구성할 수 있는데,
매일 생성되는 로그를 일단위로 수집한다면 바로 하둡으로 보낼 수 있다.
(예를들어 스마트카의 상태정보를 일 단위로 수집 후 적재)
그런데, 실시간 운행정보와 같이 로그가 실시간으로 쏟아지는 경우는 바로 하둡으로 적재할 수 없을 것이다. 데이터가 무자비 하게 쏟아지면 시스템이 장애가 발생해 데이터까지 유실 될 수 있기 때문인다. 이런 경우에 버퍼링 처리를 위해 카프카를 사용하게 된다.
2. 카프카
카프카는 메시지성 데이터를 비동기식으로 중계한다. 대규모 트랜잭션 데이터가 발생시 중간에 데이터를 버퍼링 하면서 시스템에 안정적으로 전송해준다. 플럼이 수집한 데이터를 비동기로 전송하기 때문에 수집속도가 빨라지는 장점도 있다. 무조건 주키퍼를 통해 이용.
- Broker : 카프카의 서비스 인스턴스. Broker들을 클러스터로 구성하고 Topic이 생성되는 물리적 서버.
- Topic : Broker에서 데이터의 발생/소비 처리를 하기 위한 저장소
- Provider : Broker의 특정한 Topic에 데이터를 전송하는 역할.
- Consumer : Broker의 특정 Topic에서 데이터를 수신하는 역할.

업무 도메인이 복잡할 때는 위와 같은 구조를 사용할 필요가 없다.(카프카 서버 1개, 브로커 1개면 됨)
위 구성은 카프카 서버가 1대이므로 대량 발생/소비에 사용하기는 어렵지만, 업무도메인이 복잡해서 메시지 처리를 분리해서 관리할 필요가 있을때 사용된다. 대량 발행, 소비가 필요하다면 2대 이상의 카프카 서버로 멀티 브로커를 만들어야한다.(아래 그림) 물리적으로 나누어진 브로커 간에 데이터 복제가 가능하기때문에 안전성도 높다.

카프카 한 줄요약.
| 플럼이 실시간 데이터를 수집해서 카프카 토픽에 전송하면, 카프카는 토픽에 임시 저장한다. 이 후 컨슈머 프로그램이 작동하면 토픽에서 데이터를 꺼내간다. |
페이지 요약.
로그 파일을 수집할 때는 이벤트를 감지하여 플럼이 수집한다. 이때 가비지 데이터는 Interceptor를 통해 필터링한다.
배치성 로그를 받아오는 플럼에이전트는 Sink를 HDFS로 데이터로 보내고
실시간 로그를 받아오는 플럼에이전트는 실시간 로그는 비동기 처리로 Sink를 통해 카프카 Topic에 전송한다.
추가정보 (코드를 통해 알게된 사실 정리)
1. 플럼
1) 플럼의 Channel의 종류는 크게 Memory와 파일이 있다.
- Memory 채널은 데이터를 메모리상에 중간적재하므로 성능이 높지만 안정성이 낮다.
- File채널은 Source에서 전송한 데이터를 받아서 로컬 파일 시스템 경로에 저장해두기 때문에 성능은 낮지만 안정성이 높다.
2) 플럼 Source
- 배치성 로그 파일 이벤트 감지 : 플럼 Source컴포넌트의 SpoolDir을 통해 감지.
- 실시간 로그 발생 감지 : 플럼의 Source중 Exec-Tail을 이용
3) 플럼 Intercepter
- type을 regex_filter로 설정해서 지정한 정규화식으로 필터링 가능
2. 카프카
1) 토픽 생성
kafka-topics --create --zookeeper 서버명 --replication-fator N --partitions N --topic 토픽명
- replication-factor : 다중 브로커로 만들고 설정값만큼 복사한다.
- partitions : 해당 토픽에 데이터들이 파티션 개수만큼 분리 저장된다. (다중 브로커에서 읽기/쓰기 성능 향상을 위해 사용)
* 토픽 삭제
kafka-topics --delete --zookeeper 서버명 --topic 토픽명
2) Producer사용
카프카 서버에 ssh접속 후 명령 실행
kafka-console-producer --broker-list 서버명 -topic 토픽명
메세지 입력
-> 입력한 메세지가 토픽을 전송됨 (consumer를 통해 가져올 수 있다.)
3) Consumer사용
kafka-console-consumer --zookeeper 서버명 --topic 토픽명 --from-beginning
토픽에 있던 메시지를 가져와서 출력한다.
(여러 터미널에서 실행하면 모두 동일 메시지를 가져온다. - consumer여러개 가능)
'DataEngineering > 하둡' 카테고리의 다른 글
| 실시간 적재에 사용되는 기술 - HBase, 스톰, 에스퍼... (0) | 2020.12.27 |
|---|---|
| [빅데이터] - 하둡과 주키퍼 (대용량 로그파일 적재) (0) | 2020.12.15 |
| [HADOOP] 하둡이란? (0) | 2020.09.27 |


