
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 프로그래머스 큰 수 만들기
- EMR 구조
- ORACLE MSSQL차이
- 프로그래머스힙
- 문맥교환
- 카프카
- Spark
- 데이터베이스복사
- 데이터파이프라인
- 서버간 복사
- 런타임데이터영역
- Spark 최적화
- ORACLE문법
- 하둡
- 스파크
- 프로그래머스
- 실행엔진
- Catalyst Optimizer
- 지연연산
- freenom
- 하둡1.0
- Databricks
- lazy evaluation
- kafka 설치
- 데이터엔지니어링
- AWS Crawler
- 하둡2.0
- 데이터 수집
- 빌드도구
- 하둡에코시스템
- Today
- Total
띵유로그
[SPARK] 스파크 기본 아키텍쳐 본문
스파크의 기본 아키텍쳐에 대해 알아보겠습니다.
스파크는 컴퓨터의 리소스를 관리하는 Cluster Manger와 그 위에 동작하는 Spark application으로 구성되어있습니다.
1. 클러스터 매니져
클러스터 매니져는 스파크 어플리케이션의 리소스를 효율적으로 분배하는 역할을 합니다.
스파크는 태스크를 할당하기 위해 클러스터 매니져에 의존합니다.
할당가능한 excutor를 전달받으면 그대로 할당하는 역할만을 수행하기 때문에 매우 중요합니다.
클러스터 매니져는 스파크와 떼었다 붙일 수있고
3.0기준으로 스파크 standalone 클러스터 매니저, 하둡 YARN, 메소스, Kubernetes 등이 사용가능합니다.
각 종류에 대해 잘 정리되어있는 글이 있어 남겨둡니다.
https://paranwater.tistory.com/414
Spark Cluster Manager Types (스파크 클러스터 매니저 타입 3종류 번역)
Spark Cluster Manager Types 3종류를 발번역 하였습니다 전체적인 흐름을 파악하는데 참고해주세요 스파크 워드 카운트 소스코드 주석달면서 분석중 http://paranwater.tistory.com/416 원문 페이지 주소 : htt..
paranwater.tistory.com
클러스터 매니져 별 특징에 대해서는 다음에 정리하도록하고, 이번 포스팅에서는 스파크에 대해서만 다루겠습니다.
2. 스파크 어플리케이션
사용자가 클러스터 매니저에 spark application을 제출하면 클러스터 매니져가 자원을 할당하는 방식입니다.
이때 제출하는 스파크 어플리케이션은 드라이버 프로세스와 익스큐터 프로세스로 구성되어있습니다.
| 구성 | 역할 |
| 드라이버 프로세스 | - main 함수 실행 - 스파크 application 정보 유지, 관리 - 입력에 대한 응답 - 익스큐터 프로세스 작업과 관련된 분석 - 배포, 스케쥴링 |
| 익스큐터 프로세스 | - 드라이버 프로세스가 할당한 작업 수행 - 작업 보고 |
정리하면 아래 그림과 같습니다.
spark session 을 통해 익스큐터에게 작업을 할당합니다. 그리고 드라이버 프로세스, 익스큐터 모두 클러스터에서 실행되기때문에 클러스터 매니져의 관리를 받습니다.
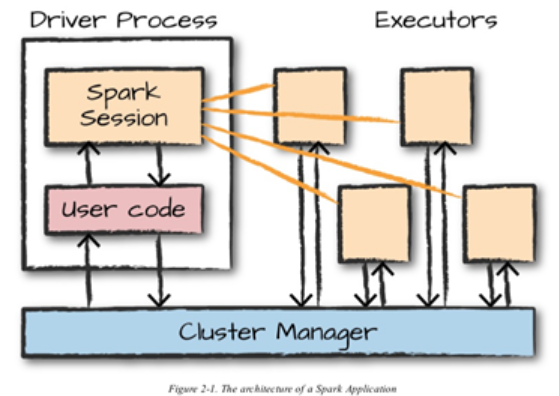
3. SPARK Session
스파크 application 은 SPARK SESSION 이라고 불리는 드라이버 프로세스로 제어합니다.
spark session 은 익스큐터에 태스크를 전달하기 전에 JVM에서 실행할 수 있는 코드로 변환해줍니다.

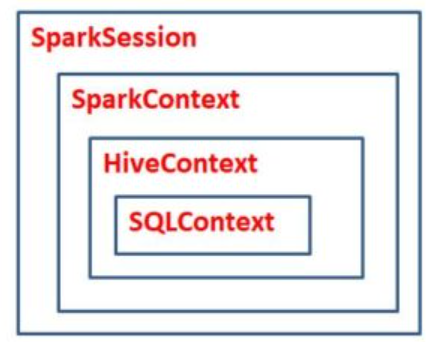
*참고로 spark 2.0.0 이전에는 Spark Context가 사용되었습니다.
spark context는 new 연산자를 통해 만들고,
spark session 은 빌더로 만듭니다. 이미 session 이 존재한다면 중복으로 만들지 않습니다.
spark context가 있는데 spark session 이 필요한 이유는
원래 직접 spark context를 만들어서 접근했으나, 여러명의 사용자가 같은 spark context에 접근했을 때의 문제가 있었기 때문입니다. 또 개발자가 context를 만드는걸 신경쓰지 않아도 되니 편해졌습니다.
한줄 요약 : 사용자가 spark-submit 을 통해 어플리케이션을 제출하면 Spark Session 을 만듭니다.
그 후 spark driver(Spark session)가 Cluster magager와 연결하여 리소스를 요청합니다.
작업을 task단위로 분할하여 excutor에 보내고 결과를 저장합니다.
'DataEngineering > SPARK' 카테고리의 다른 글
| SPARK - DATAFRAME, DATASET (0) | 2022.07.27 |
|---|---|
| [SPARK] 스파크 튜닝 방안 (0) | 2022.03.21 |
| [오류]java.lang.NoSuchMethodError: scala.reflect.internal... spark library 설정 (0) | 2022.01.12 |
| [SPAKR] note (0) | 2021.11.04 |
| [SPARK] SPARK 지연연산의 이점 (0) | 2021.08.18 |