
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Catalyst Optimizer
- 데이터엔지니어링
- 실행엔진
- 프로그래머스
- 런타임데이터영역
- 데이터베이스복사
- Spark 최적화
- 빌드도구
- 문맥교환
- Spark
- 하둡
- 스파크
- 하둡2.0
- 하둡에코시스템
- 하둡1.0
- 프로그래머스 큰 수 만들기
- kafka 설치
- ORACLE MSSQL차이
- 프로그래머스힙
- Databricks
- freenom
- ORACLE문법
- 데이터 수집
- AWS Crawler
- 서버간 복사
- 데이터파이프라인
- 지연연산
- lazy evaluation
- EMR 구조
- 카프카
- Today
- Total
띵유로그
[데이터파이프라인]elastic search 본문
Elasticsearch를 간단하게 사용해보겠습니다.
Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진입니다.
방대한 양의 데이터 거의 실시간( Near Real Time )으로 저장, 검색, 분석할 수 있습니다.
Elasticsearch는 단독으로 사용되기도 하며, ELK( Elasticsearch / Logstatsh / Kibana )스택으로 사용되기도 합니다.
ELK스택에서 Elasticsearch의 역할은 간단하게 말하면, 정보를 검색, 집계하여 필요한 정보를 획득한다고 할 수 있겠습니다.

EC2 서버에 logstash 를 설치해서 S3 -> elastic search 로 데이터를 옮겨온 후 kibana 로 데이터를 표출해보겠습니다.
1. AWS Opensearch 시작하기(elastic search 시작하기)
Create 할때 아래 설정을 제외하고 모두 기본 설정을 유지했습니다.
배포유형 - 개발 및 테스트
데이터 노드의 인스턴스 유형 - t3.medium.search
네트워크 - 퍼블릭액세스(테스트용이기 때문에 퍼블릭으로 했습니다.)
세분화된 액세스 제어 - 마스터 사용자 설정
액세스 정책 - 세분화된 액세스 제어만 사용
2. EC2 띄우기 & jdk, logstash 설치
logstash 가 메모리를 많이 요구한다고 합니다.
그래서 저는 t3.medium 으로 생성했습니다.
1) 생성된 EC2 인스턴스에 연결해서 jdk를 설치해줍니다.
2) logstash 도 설치합니다.
3) logstash 압출 풀기 & 링크 걸기 & 환경변수 잡아주기
- 압출 풀기 : tar xvzf logstash-7.4.0.tar.gz
- 링크 걸기 :
- 어디서든 실행이 가능하도록 시스템 환경변수에 등록해주기 :
~/.bash_profile 에 아래 PATH를 추가해줍니다.
export LS_HOME=/home/ec2-user/logstash
PATH=$PATH:$LS_HOME/bin

4) logstash 설치 확인
logstash --version 실행 후 버전이 잘 나오면 설치가 잘 된것입니다.
3. elastic search에 올릴 데이터 확인
Elasticsearch에 올릴 데이터를 확인합니다. 저는 S3에 미리 저장해둔 데이터를 사용하겠습니다.
참고로 제가 생성해둔 데이터는 timestamp를 가지고 있는 데이터입니다.
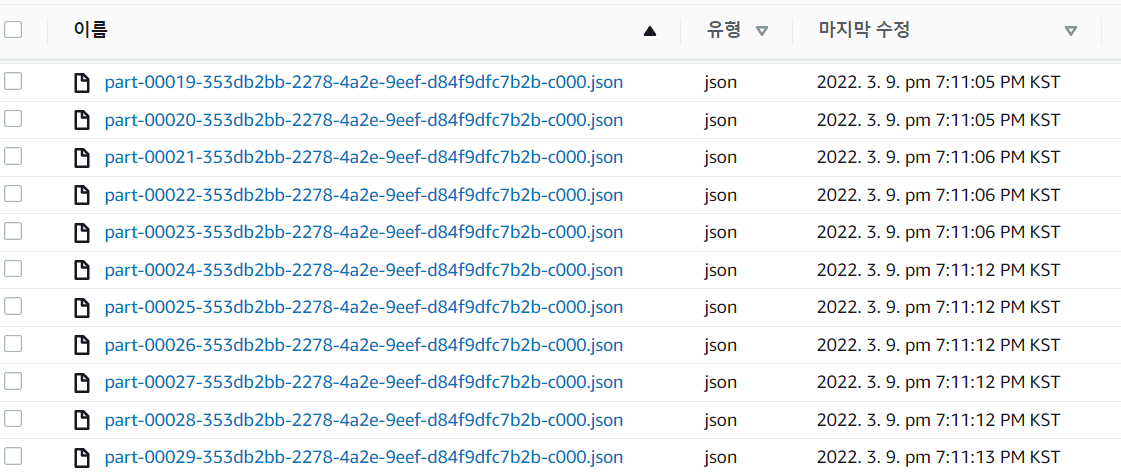
4. logstash를 통해 S3 데이터를 ElasticSearch 로 보내기
ElasticSearch 대시보드에서 확인하면 아래와 같은 정보를 볼 수 있습니다.
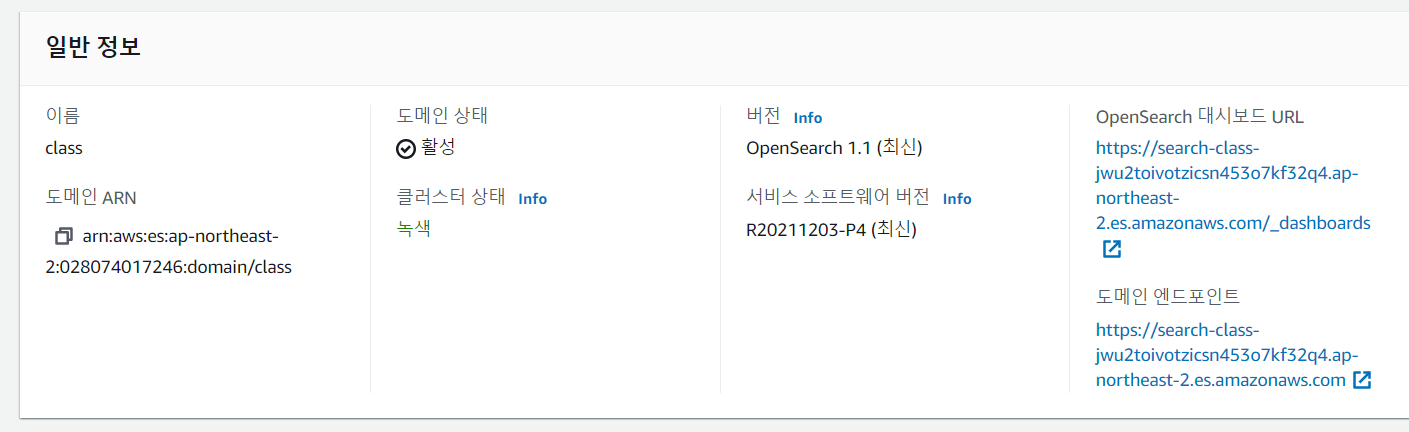
OpenSearch대시보드 : Kibana에서 접근할 endpiont 입니다. url 을 타고 들어가면 Kibana에 로그인하라고 뜹니다.
도메인 엔드포인트 : elasticsearch 로 데이터를 보낼때 사용할 endpoint
1) Kibana 확인
2) producer.conf 파일 만들기
producer.conf 파일을 작성해줍니다.
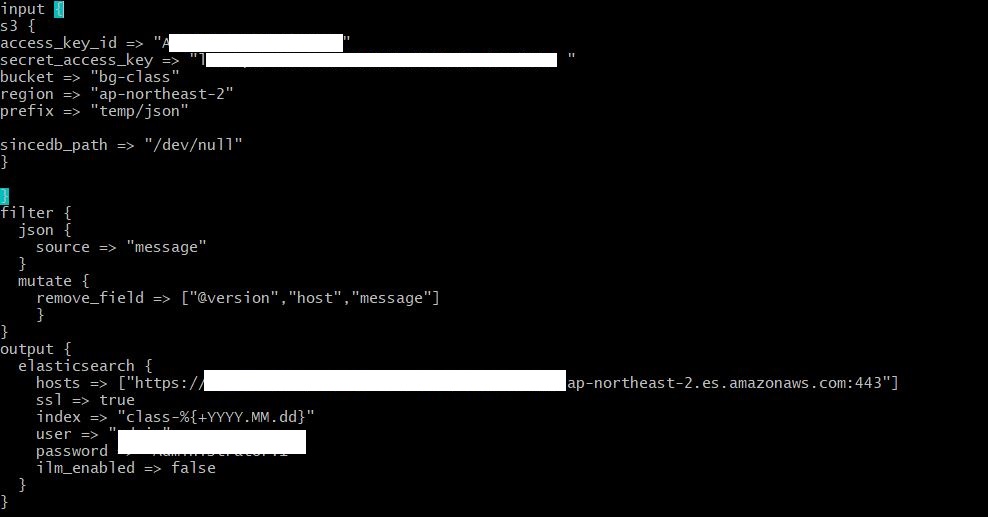
input
- S3의 액세스키,시크릿액세스키를 적어줬습니다.
- bucket : 버킷명
- region : 리전명
- prefix : 폴더명
- sincedb_path : (생략가능)
filter
- mutate : 변형시킬 내용 (remove_field를 지정하여 지울 필드를 설정해줬습니다.)(생략가능)
* mutate, date,grok
output
- elasticsearch 로 보내겠습니다.
- hosts : 도메인 엔드포인트 링크
- index : DB 파티셔닝이라고 생각할 수 있습니다.
날짜별로 인덱싱하여 오래된 날짜는 삭제하도록 정책을 설정할예정입니다.
- user/password : elasticsearch 생성시 설정한 계정
* 테스트를 위해 임시로 콘솔에서 확인하고 싶다면 output에 elasticsearch 대신 아래와 같이 써주면 됩니다.
output {
stdout {codec=>rubydebug}
}
3) logstash로 elasticsearch로 보내기 & 확인
- logstash 명령어 실행

- 수집 결과 간단하게 확인
OpenSearch 대시보드 URL 링크를 통해 Kibana로 들어갑니다.
왼쪽 상단 menu에서 Management -DevTool 클릭 후 console 실행을 눌러주면 수집 되고있는 데이터를 확인 할 수 있습니다.
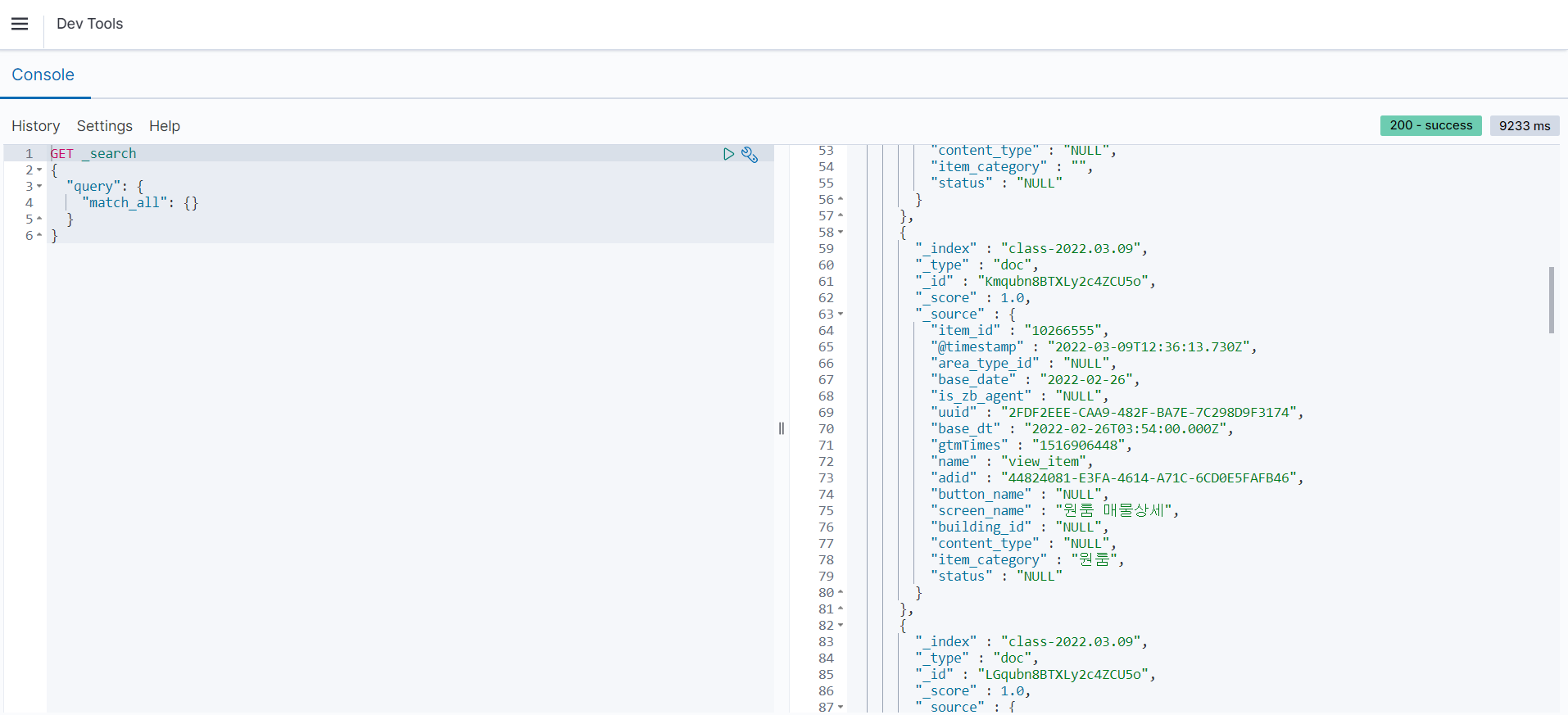
5. 데이터 인덱싱
1) 인덱스 패턴 만들기
여기서 인덱스는 RDBMS의 테이블과 유사한 개념입니다.
여러 인덱스를 하나 의 테이블 처럼 보면서 확인할 수 있도록 class*로 인덱스 패턴을 만들어줍니다.
Stack Managent메뉴 - Index Patterns 를 선택합니다.
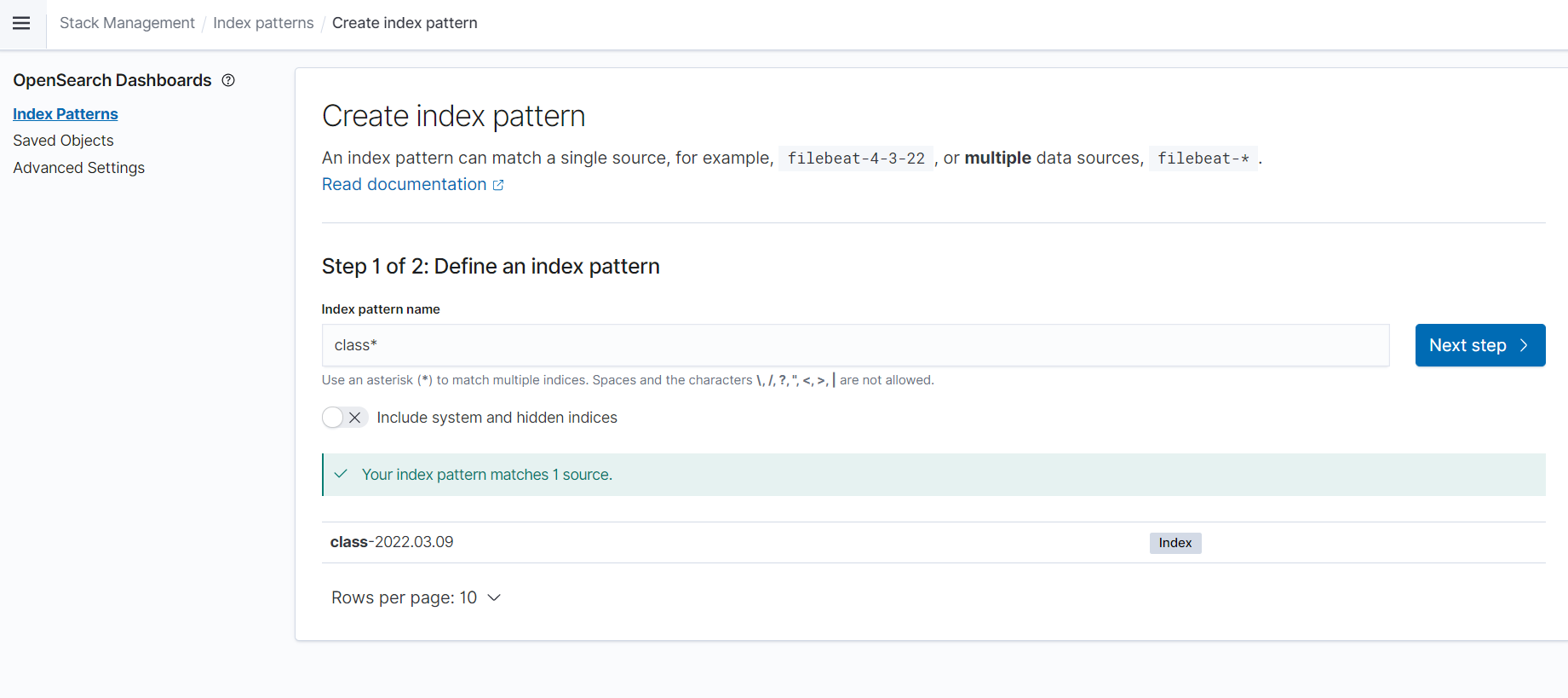
생성된 Index 를 확인할 수 있습니다.지금은 하나밖에 없습니다.
2) 시계열 필드 설정
어플리케이션에서 데이터를 발생시킨 시간인 base_dt를 시계열 필드로 설정하겠습니다.
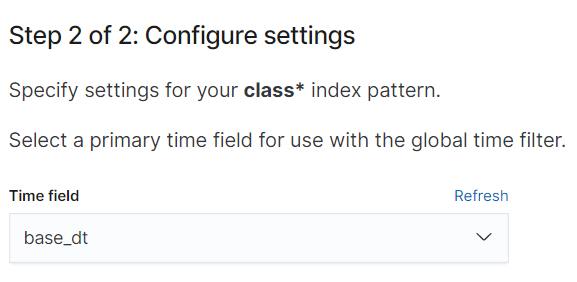
3) 확인
생성한 인덱스의 필드들을 확인합니다.
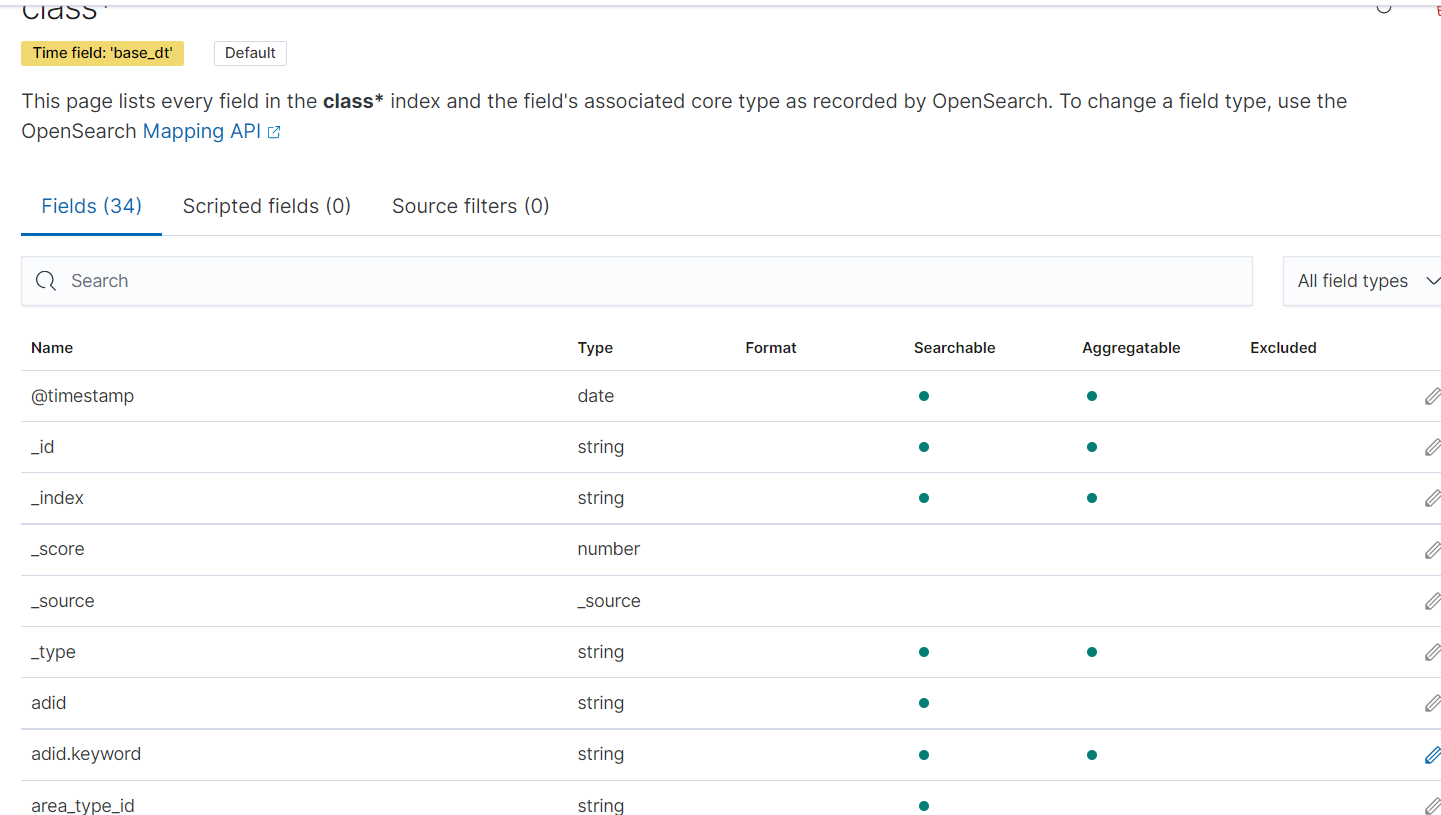
5. Kibana에서 데이터 발생 확인
Discover메뉴를 선택하여 데이터 발생을 확인합니다.
오른쪽 상단에 Show dates에서 지난 1년으로 설정해주었습니다.
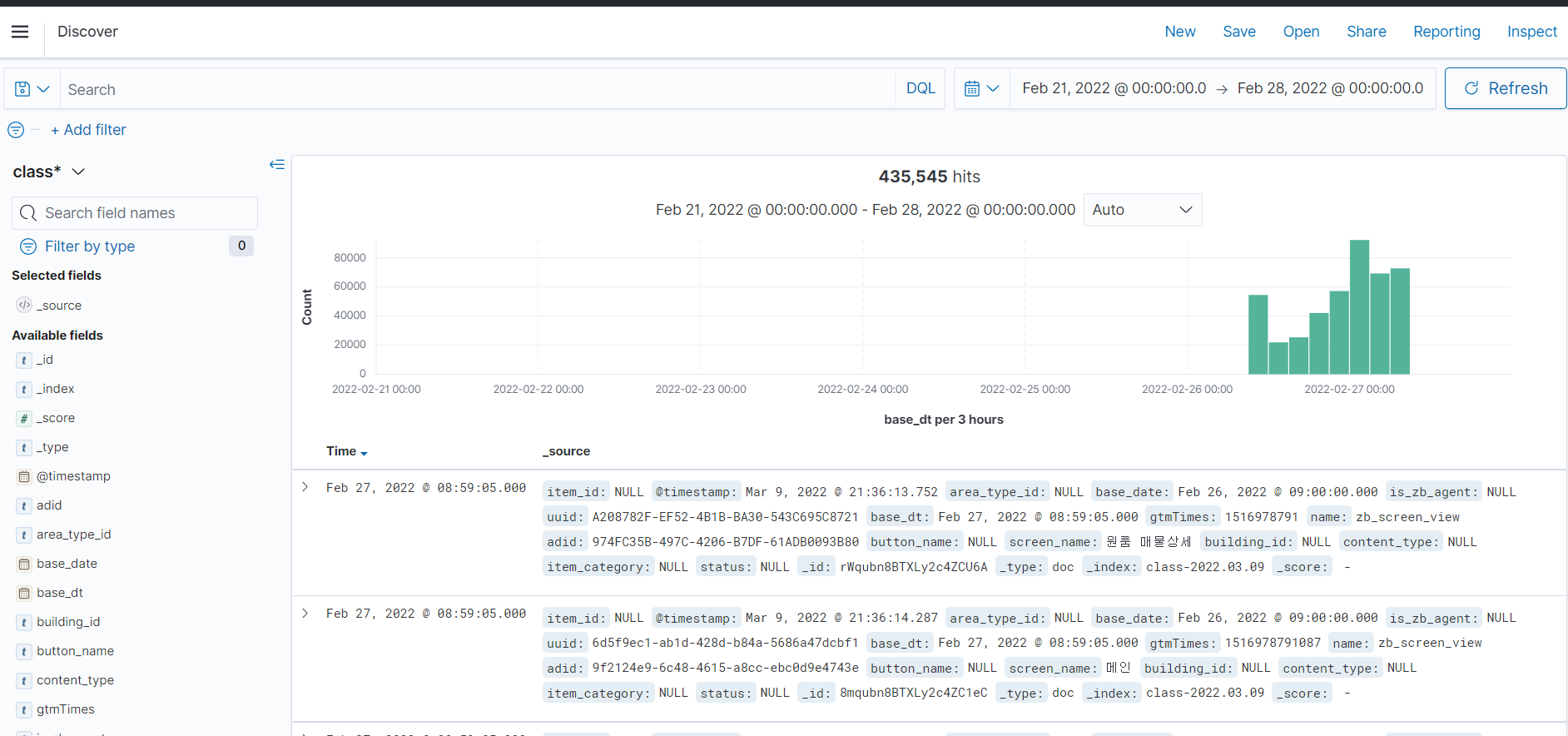
각 레코드 옆의 > 버튼을 누르면 테이블 형태로도 볼 수 있습니다.
상단에 DQL버튼을 눌러 SQL로도 분석할 수있습니다.
이제 kibana를 통해 visualization, 분석등 다양한 작업을 할 수 있습니다.
'DataEngineering' 카테고리의 다른 글
| pandas NULL이 있는 행 출력 (0) | 2023.04.05 |
|---|---|
| [데이터파이프라인] Presto - Mysql 연동 (0) | 2022.03.01 |
| [데이터파이프라인] Presto (0) | 2022.02.28 |
| [데이터파이프라인] Glue (0) | 2022.02.22 |
| [데이터파이프라인] AWS Glue Crawler 시작하기 (0) | 2022.02.17 |


