
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 하둡2.0
- 데이터베이스복사
- lazy evaluation
- AWS Crawler
- Spark 최적화
- 프로그래머스
- freenom
- EMR 구조
- 문맥교환
- 런타임데이터영역
- ORACLE문법
- 프로그래머스힙
- Spark
- 데이터엔지니어링
- 스파크
- 프로그래머스 큰 수 만들기
- 지연연산
- 카프카
- kafka 설치
- 하둡에코시스템
- ORACLE MSSQL차이
- 데이터 수집
- 하둡1.0
- Catalyst Optimizer
- 데이터파이프라인
- Databricks
- 서버간 복사
- 빌드도구
- 실행엔진
- 하둡
Archives
- Today
- Total
띵유로그
[데이터 파이프라인-2] Kinesis 구성하기 본문
반응형
1. Kinesis 데이터스트림 구성

2. 컨슈머 설정 (Firehorse)

Delivery streams 항목 -> Create delivery stream
2-1. Firehorse (consumer 역할)상세 설정사항
설정하는 방법은 쉽다.그냥 source와 destination을 지정해주면 된다.
Source : 키네시스 데이터 스트림
Destination : S3
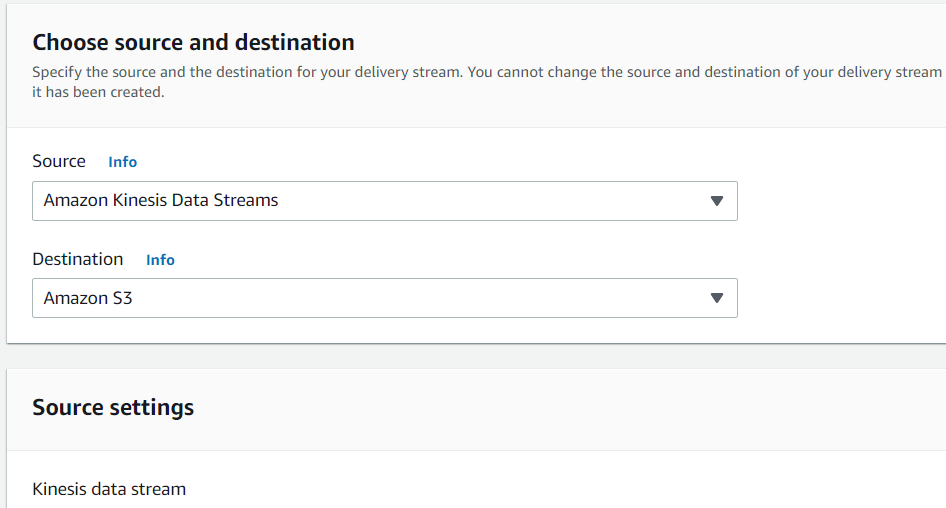
가져올 스트림의 이름을 적어준다. (스트림 이름 : class-stream)
가져올 때 람다 transformation 도 할 수 있으나 여기서는 하지 않았다. (disable)

Data 형식도 바꿀 수 있다. bigdata format인 Parquet와 ORC로 바꿀 수 있다.
(Avro 와 함께 분산 처리, 저장하는 포맷으로 binary 압축된 포맷 )
https://www.datanami.com/2018/05/16/big-data-file-formats-demystified/
또 Glue라는 어플리케이션으로 보내 ETL 작업을 추가로 할 수 있다. (다음에 glue에 대해서도 따로 공부해야겠다.. 잘 알아두면 쓸 일이 많을 듯)

반응형
'DataEngineering' 카테고리의 다른 글
| [데이터 분석 파이프라인] EMR 구조와 실행 (0) | 2022.02.12 |
|---|---|
| [데이터파이프라인-2] Api gateway, Kinesis 테스트 (0) | 2022.02.06 |
| [데이터파이프라인 - 2]AWS API Gateway 구성하기 (0) | 2022.01.29 |
| [데이터파이프라인] Logstash 구성 및 twitter 연결 (0) | 2022.01.17 |
| [데이터파이프라인]kafka 설치 ~ 토픽생성 (0) | 2022.01.16 |
'DataEngineering' Related Articles
more




Comments