
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Databricks
- lazy evaluation
- 데이터 수집
- AWS Crawler
- 하둡에코시스템
- 데이터엔지니어링
- 데이터파이프라인
- 프로그래머스 큰 수 만들기
- 프로그래머스힙
- kafka 설치
- Spark 최적화
- ORACLE MSSQL차이
- 스파크
- 하둡1.0
- Catalyst Optimizer
- 빌드도구
- 카프카
- 지연연산
- EMR 구조
- 하둡
- 실행엔진
- 하둡2.0
- 런타임데이터영역
- 문맥교환
- ORACLE문법
- 데이터베이스복사
- 프로그래머스
- freenom
- Spark
- 서버간 복사
- Today
- Total
띵유로그
[데이터파이프라인-2] Api gateway, Kinesis 테스트 본문
1. EC2 에 접속해서 curl 명령어 실행
Apigateway에서 호출할 url 을 확인 합니다.

curl 명령어를 통해 테스트 합니다.
curl -d "{\"value\":\"30\",\"type\":\"Tip 3\"}" -H "Content-Type: application/json" -X POST https://url~~~
정상적 결과는 아래와 같습니다.

2. cloud watch 에서 확인
참고) 배포된 stage에서 미리 cloud watch 로그 추척을 활성화 시켰어야 확인 가능합니다.
로그 그룹 확인 후 API-Gateway-Excution-Logs~~ 클릭합니다.

curl 명령어를 통해 POST 요청 1회만 보냈기 때문에 로그는 하나가 남아있습니다.
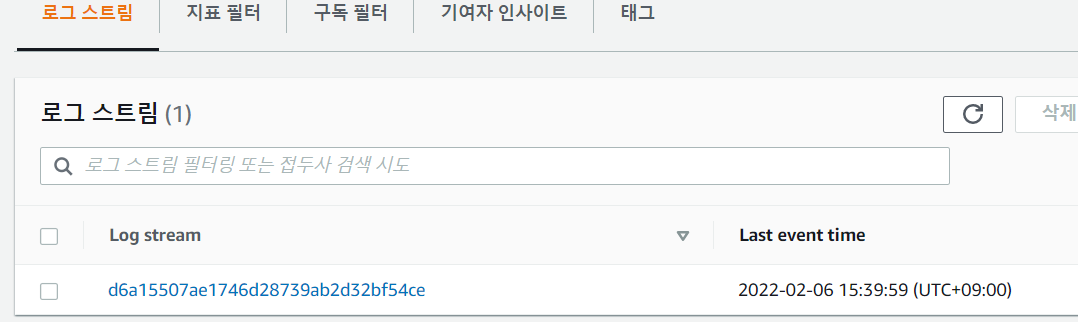
여기 까지 확인이 완료되면 APIgateway 구성이 정상적으로 완료되었다는 뜻입니다.
POST 요청이 들어오면 Apigateway가 잘 응답하였으니, 이제 들어온 로그를 Kinesis가 잘 받고있는지 확인할 차례입니다.
1. AWS Kinesis 접속
Kinesis 서비스에 접속해서 그래프를 통해 데이터가 잘 들어오고 있는것을 확인합니다.
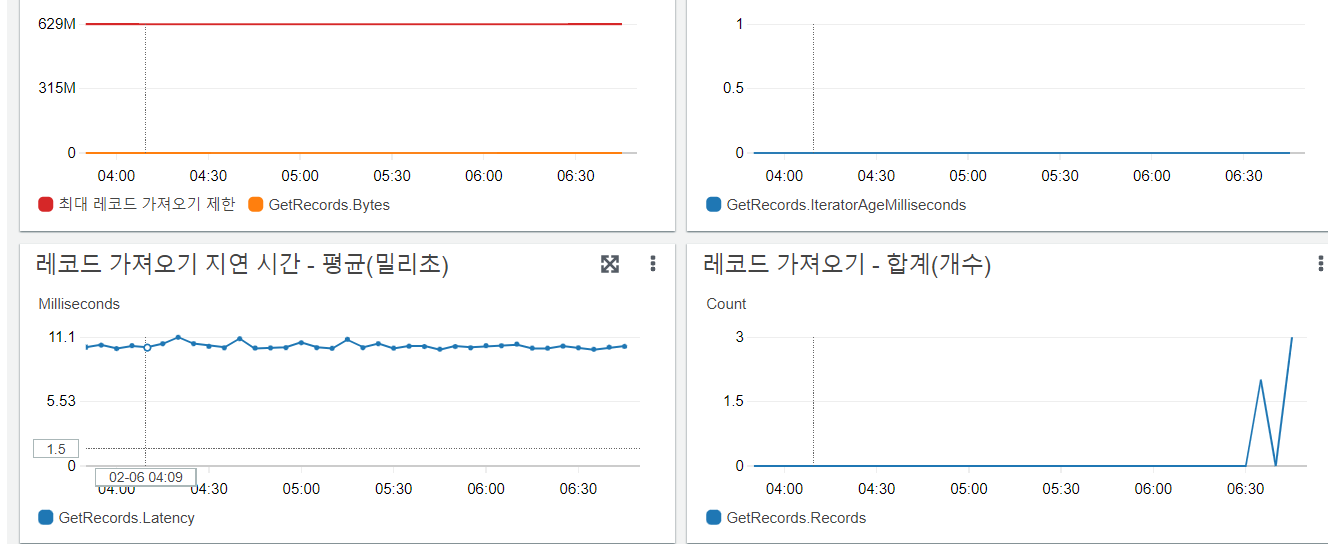
Kinesis Firehose(Delivery stream)을 확인해서 S3로도 잘 저장되고 있는것을 확인합니다.
class-stream 클릭 후 그래프를 통해 확인할 수도 있고 Destination(bg-class)를 클릭해서 직접 S3에 저장된 것을 확인할 수도 있습니다.
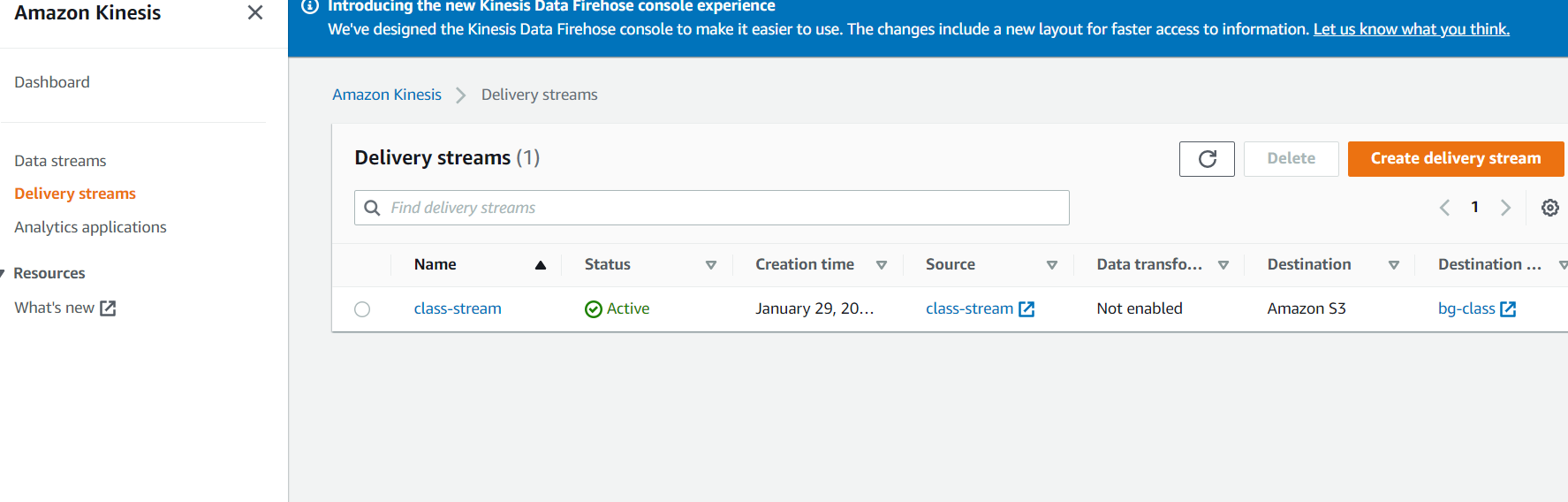
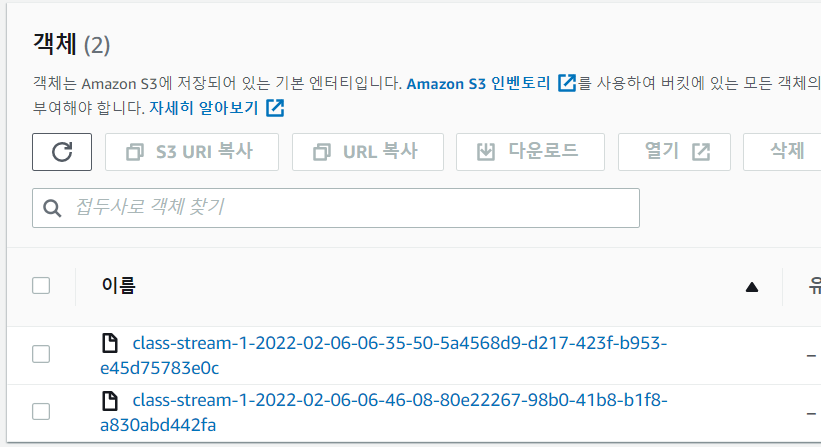
이제 모든 준비가 완료되었으니 실제 application에서 발생시킨 로그를 apigate에서 수집후에 S3에 적재한다고 가정하고 Test를 해보겠습니다.
Application은 test를 위해 작성된 jar 파일이며, csv에서 11건의 데이터를 읽어와 입력한 url 에 POST방식으로 송신합니다.
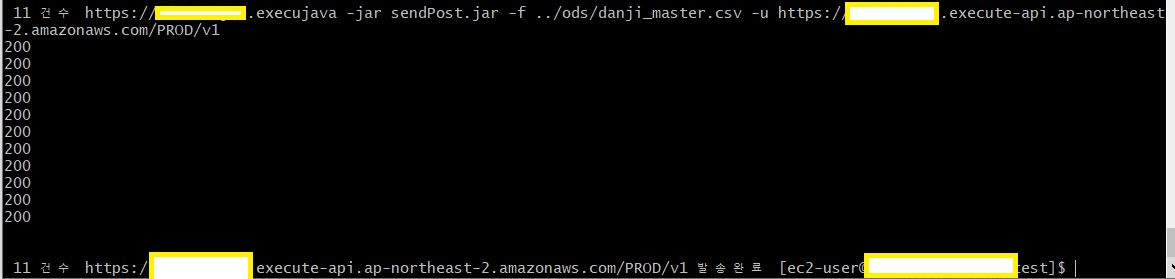
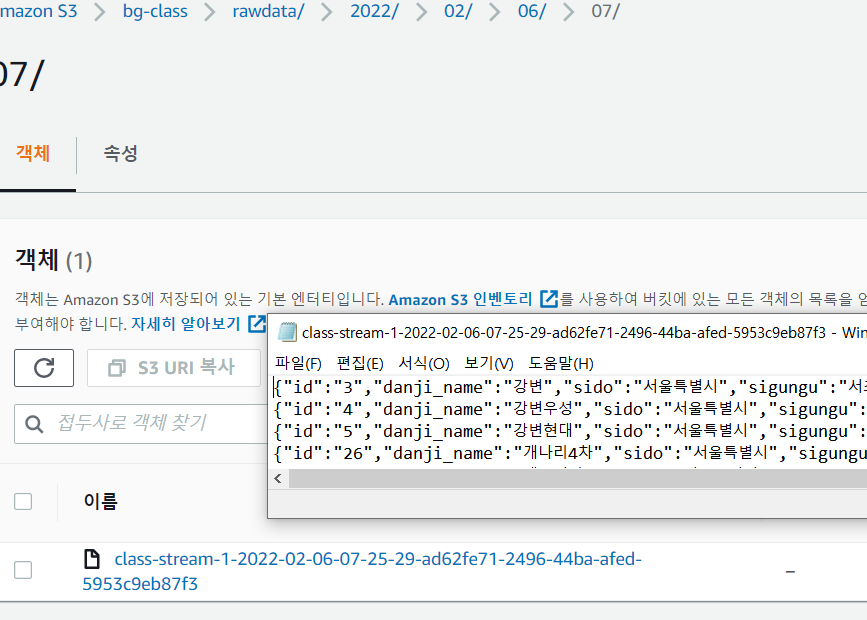
이렇게 정상적으로 S3에 데이터가 수집된 것을 확인했습니다.
'DataEngineering' 카테고리의 다른 글
| [데이터파이프라인] EMR에서 Spark 모니터링(Ganglia) (0) | 2022.02.12 |
|---|---|
| [데이터 분석 파이프라인] EMR 구조와 실행 (0) | 2022.02.12 |
| [데이터 파이프라인-2] Kinesis 구성하기 (0) | 2022.01.29 |
| [데이터파이프라인 - 2]AWS API Gateway 구성하기 (0) | 2022.01.29 |
| [데이터파이프라인] Logstash 구성 및 twitter 연결 (0) | 2022.01.17 |



