
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 하둡에코시스템
- 데이터 수집
- 프로그래머스 큰 수 만들기
- 데이터베이스복사
- ORACLE MSSQL차이
- lazy evaluation
- EMR 구조
- 프로그래머스힙
- 하둡2.0
- Spark
- Catalyst Optimizer
- ORACLE문법
- freenom
- AWS Crawler
- 카프카
- 런타임데이터영역
- 스파크
- 서버간 복사
- 프로그래머스
- 데이터파이프라인
- Databricks
- 하둡
- Spark 최적화
- 실행엔진
- 문맥교환
- 데이터엔지니어링
- 빌드도구
- 하둡1.0
- kafka 설치
- 지연연산
- Today
- Total
띵유로그
[데이터파이프라인]kafka 설치 ~ 토픽생성 본문
트위터에서 발생한 데이터를 kafka로 보내는 과정을 직접 해보려합니다.
먼저 aws에서 t2.medium 으로 인스턴스를 하나 시작했습니다. 인스턴스 시작하는 과정은 포스팅에 포함하지 않았습니다.
1. 자바 설치
카프카는 자바 기반이기 때문에 자바를 설치해주어야 합니다.



java 가 잘 설치된걸 확인했다면 이제 wget명령어를 통해 kafka 를 설치해줍니다.
2. kafka 설치

똑같이 명령어를 실행시켰는데 에러가 나면 dlcdn.apache.org 홈페이지에 들어가서 파일 경로가 달라진건아닌지, 오타가 있지는 않는지 확인해봅니다.
https://dlcdn.apache.org/kafka/3.0.0/
Index of /kafka/3.0.0
dlcdn.apache.org

그 후 압축을 풀어줍니다.

추가) 링크를 걸어주면 앞으로 편하게 접근할 수 있습니다.
(나중에 카프카 버전이 바뀌었을 때에도 같은 configuration으로 사용할 수 있습니다.)
저는 해당 폴더에 kafka로 링크를 걸겠습니다.


3. 주키퍼, 카프카 서버 시작
(이번에 클러스터 여러개를 만들진 않았지만,,,)클러스터간 통신을 위해 주키퍼를 실행합니다.


데몬이 잘 실행되는지 확인합니다.


kafka 서버가 다른 서버와 통신할때 사용하는 포트인 9092번 포트(물론 설정시 바꿀 수 있긴함)
zookeeper client 포트인 2181 포트가 Listening 상태인것을 확인할 수 있습니다.
당연히 aws 에서 보안그룹에 9092 포트는 열어줘야합니다.
4. 카프카 토픽 생성
이제 토픽을 생성할 차례입니다.

브로커를 1개만 두었기 때문에 replication factor도 1입니다. (브로커 확장은 다른 포스팅으로 하겠습니다.)

정상적으로 토픽이 생성되었는지 확인하겠습니다.


5. 카프카 동작 확인
동작하는 것을 확인하기 위해 producer/consumer를 하나 띄우겠습니다.
1) consumer 띄우기
먼저 consumer를 띄워보겠습니다. 편의상 consumer 서버를 따로 두지 않고 카프카 서버에서 바로 consumer를 띄웠습니다.

2) producer 띄우기
producer는 개인적으로 서버를 미니 만들어두었습니다. 미리 만들어둔 서버에서 producer를 띄워보겠습니다.
(카프카 서버와 마찬가지로 producer 서버에도 java, kafka가 설치되어있어야합니다.)
producer는 카프카 서버와 다른 서버이기 때문에 target 서버 주소를 적어줘야합니다.
명령어 : bin/kafka-console-producer.sh --topic twitter --bootstrap-server IP주소:9092
카프카 서버, 프로듀서 서버 모두 aws인 경우 내부 통신이기때문에 public 주소가 아닌 private 주소를 적어줘야합니다.
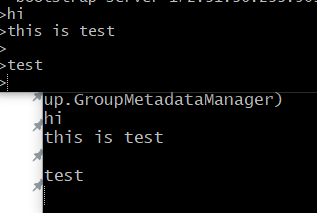
다음과 같이 producer 에서 입력한 단어들(위) 이 consumer(아래)에서 잘 수집되는것을 볼 수 있다.
참고) ctrl + d : producer 종료
'DataEngineering' 카테고리의 다른 글
| [데이터 분석 파이프라인] EMR 구조와 실행 (0) | 2022.02.12 |
|---|---|
| [데이터파이프라인-2] Api gateway, Kinesis 테스트 (0) | 2022.02.06 |
| [데이터 파이프라인-2] Kinesis 구성하기 (0) | 2022.01.29 |
| [데이터파이프라인 - 2]AWS API Gateway 구성하기 (0) | 2022.01.29 |
| [데이터파이프라인] Logstash 구성 및 twitter 연결 (0) | 2022.01.17 |



